How LSTMs architecture solves the problem created by RNNs

Hi, I am Japkeerat. I am working as a Machine Learning Engineer since January 2020, straight out of college. During this period, I've worked on extremely challenging projects - Security Vulnerability Detection using Graph Neural Networks, User Segmentation for better click through rate of notifications, and MLOps Infrastructure development for startups, to name a few. I keep my articles precise, maximum of 4 minutes of reading time. I'm currently actively writing 2 series - one for beginners in Machine Learning and another related to more advance concepts. The newsletter, if you subscribe to, will send 1 article every Thursday on the advance concepts.
Recurrent Neural Networks had a problem - vanishing gradient problem. Why the problem exists is better discussed in the previous article. In a brief, the vanishing gradient problem implies that the context of the sentence is forgotten about too quickly.
To fix the problem of Vanishing Gradient, Long-Short Term Memory (LSTM) Networks were introduced. LSTM maintains the context in 2 different ways - Long Term Memory and Short Term Memory. Both have a different purpose.
Before diving into the architecture and representation of LSTMs, it is important to understand the concept of Short Term and Long Term Memory and what exactly does it do.
Short Term Memory to put it simply, keeps the latest information in the memory that is important for making predictions.
Long Term Memory is used to keep important information in context while making prediction for a long time. Basically, it is a persistent storage of all the important keywords in the data.
Here’s an extremely rough approximation of how it looks.
How LSTMs do the magic?
This overwhelming diagram below is a representation of a cell in LSTM.
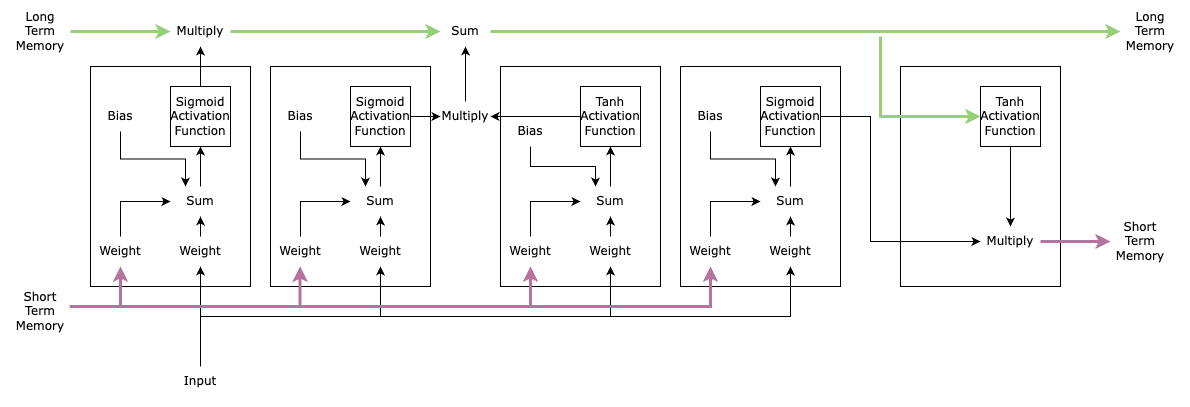
The line on top, the green one, that is what is called Cell State which essentially is the Long Term Memory.
The line on bottom, the pink one, that is the Hidden State which, if you are following along could guess, is Short Term Memory.
Slowing down for a second. We were discussing the RNN problems. How does the Cell State and Hidden State solve it? Well, if you look closely, there is no weight to Cell State. Meaning, there is absolutely no chance of gradient to explode or vanish, something that is possible in the case of RNNs.
Moving on, let’s label the diagram for better understanding.
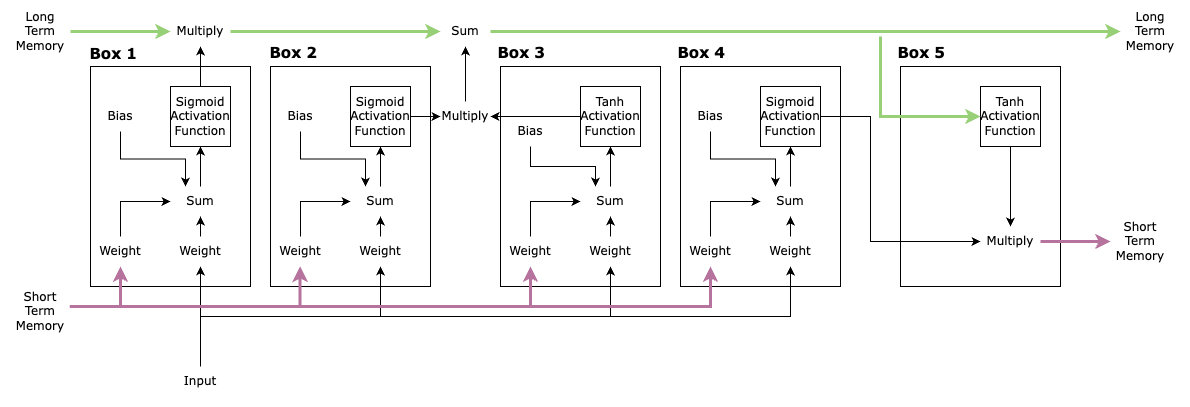
The box 1 is a way to determine the impact of input and the short term memory on the long term memory. It controls how much of the long term memory needs to be remembered. Hence, it is also known as Forget Gate.
The box 2 and 3 determines how much of the input to this unit should be remembered for the long time. Box 3 is calculating the potential long term memory for this input while box 2 is responsible for determining the “how much” part. Important to note, the only difference in both the boxes is the activation function. These 2 boxes make up what is called Input Gate.
Box 4 and 5 are responsible for calculating the Short Term Memory for the next LSTM unit. Box 5 is where the calculation of potential short term memory takes place which is done using the Long Term Memory and not the input and the “how much” aspect is calculated by box 4. These boxes make up what is called Output Gate.
So with the use of Input Gate, Forget Gate, Output Gate, Cell State, and Hidden State (that's a lot!), LSTMs solve the problem of vanishing gradient with Recurrent Neural Networks.




